 02_ケモインフォマティクス
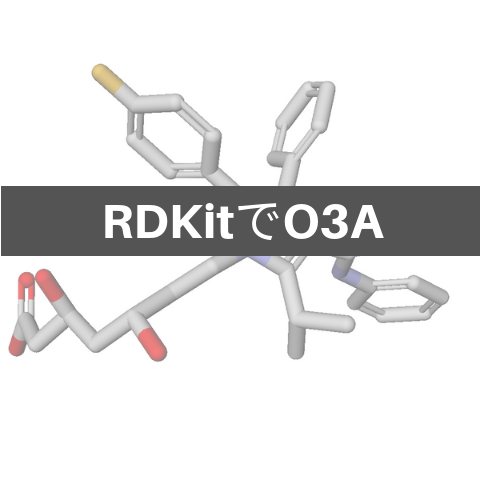
02_ケモインフォマティクス RDKitでOpen3DALIGNを用いた立体構造の重ね合わせ
異なる分子の立体構造を重ね合わせて眺めることで得られる知見が多くあります.これまで本ブログでは「RDKitによるコンフォマーの生成」という記事で,同じ分子のコンフォマーを重ね合わせて表示することを行いました.その際には鋳型となる原子の番号を指定することで重ね合わせの中心骨格を決め...
02_ケモインフォマティクス 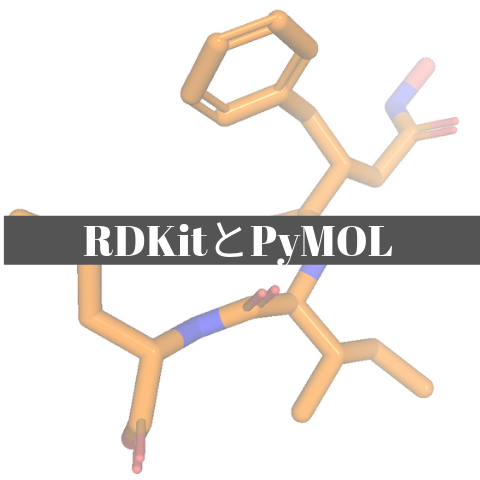 02_ケモインフォマティクス
02_ケモインフォマティクス  02_ケモインフォマティクス
02_ケモインフォマティクス  04_統計学・機械学習
04_統計学・機械学習  04_統計学・機械学習
04_統計学・機械学習  04_統計学・機械学習
04_統計学・機械学習  04_統計学・機械学習
04_統計学・機械学習 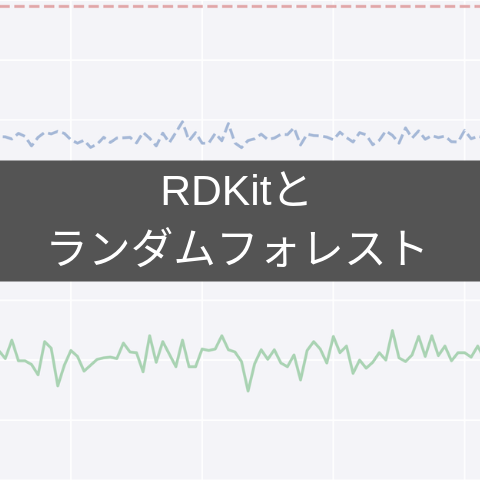 04_統計学・機械学習
04_統計学・機械学習