
統計学が大事だとはわかっていても,どこから勉強をはじめたらよいかわかりにくいと感じる人が多いのではないでしょうか?この記事から数回に渡って,pythonを使いながら統計学の基本的な考え方を頭にすり込んでいくこと目指します.数式を理解することは応用力をつけるという点では大事ですが,最初の理解のためにはコンピュータに計算させながら結果を吟味していく方が役に立つと考えているからです.
はじめに
具体的には「ハンバーガー統計学」こと,「統計学がわかる」をpythonの勉強を兼ねて読み解きます.記事は書籍に沿って進めますが,同様の内容がウェブにも公開されています.今回の記事では第1章の平均と分散を扱います.
対象とする人は平均・分散・正規分布といった基本的な単語にはなじみがあるけれども,実は高校レベルも怪しい部分がある人です.当然,統計分布や統計手法についてはほとんど覚えていないことを想定しています.
これから基本的な内容を理解・確認しながら,それをどのようにpythonで表現するかを学んでいきましょう.まずはpythonの必要なライブラリをimportします.
import numpy as np import pandas as pd import matplotlib as mpl import matplotlib.pyplot as plt
平均・分散を計算する
pandas.Series.var()
pandas.Series.std()
pandas.Series.describe()
まずはpandasのSeriesとして2つの店のポテトの長さを入力していきます.
wakuwaku = pd.Series([3.5, 4.2, 4.9, 4.6, 2.8, 5.6, 4.2, 4.9, 4.4, 3.7, 3.8, 4.0, 5.2, 3.9, 5.6, 5.3, 5.0, 4.7, 4.0, 3.1, 5.8, 3.6, 6.0, 4.2, 5.7, 3.9, 4.7, 5.3, 5.5, 4.7, 6.4, 3.8, 3.9, 4.2, 5.1, 5.1, 4.1, 3.6, 4.2, 5.0, 4.2, 5.2, 5.3, 6.4, 4.4, 3.6, 3.7, 4.2, 4.8]) mogumogu = pd.Series([4.5, 4.2, 3.9, 6.6, 0.8, 5.6, 3.2, 6.9, 4.4, 4.7, 3.8, 3.0, 3.2, 4.9, 7.6, 3.3, 7.0, 3.7, 3.0, 4.1, 5.8, 4.6, 4.0, 2.2, 7.7, 3.9, 6.7, 3.3, 7.5, 2.7, 5.4, 5.8, 5.9, 3.2, 5.1, 3.1, 6.1, 4.6, 2.2, 4.0, 6.4, 5.2, 3.3, 6.4, 6.4, 2.6, 2.6, 5.2, 5.8])
numpyのndarrayにも同様の機能がありますが,pandasではSeriesやDataFrameの
- 合計:sum()
- 平均;mean()
- 分散;var()
- 標準偏差;std()
などを簡単に求めることができます.またdescribeを使うことで基本的な統計量の一覧がすぐに算出できます.
wakuwaku.describe().round(3)
count 49.000 mean 4.571 std 0.834 min 2.800 25% 3.900 50% 4.400 75% 5.200 max 6.400 dtype: float64
mogumogu.describe().round(3)
count 49.000 mean 4.614 std 1.624 min 0.800 25% 3.300 50% 4.500 75% 5.800 max 7.700 dtype: float64
注意点としてはpandasの標準設定では分散・標準偏差は「サンプルサイズ−1」で除した不偏分散を用いています.これはddof(Degree Of Freedom)という変数によって管理されていて,標準設定は
- ddof=True
- ddof=1
です.そのため標本分散を求めたい場合は明示的にddof=0とする必要があります.
wakuwaku.var(), wakuwaku.var(ddof=0) wakuwaku.var(ddof=False), wakuwaku.var(ddof=True), wakuwaku.var(ddof=2)
(0.69499999999999995, 0.68081632653061219) (0.68081632653061219, 0.69499999999999995, 0.70978723404255317)
度数分布表とヒストグラムを作成する
度数分布表
pd.value_counts(values, sort=True)
(0,1], (1,2]…のように階級を設定して度数分布表を作成していきます.各値を階級で分類するにはpandasのcut関数を使うことで実現できます.
bins = np.arange(0,9) waku_cut = pd.cut(wakuwaku, bins)
0 (3, 4] 1 (4, 5] 2 (4, 5] 3 (4, 5] 4 (2, 3] 5 (5, 6] ・・省略・・
さらにvalue_countsを使って分類ごとに集計することで度数分布表が完成します.標準設定では度数順にソートされてしまうので,これを無効にしています.
pd.value_counts(waku_cut, sort=False)
(0, 1] 0 (1, 2] 0 (2, 3] 1 (3, 4] 14 (4, 5] 19 (5, 6] 13 (6, 7] 2 (7, 8] 0 dtype: int64
もぐもぐの方も同様にやってみましょう.
pd.value_counts(pd.cut(mogumogu,bins), sort=False)
(0, 1] 1 (1, 2] 0 (2, 3] 7 (3, 4] 13 (4, 5] 8 (5, 6] 9 (6, 7] 8 (7, 8] 3 dtype: int64
ヒストグラム
pandasを用いてヒストグラムを作成
これまで度数分布表をつくってきましたが,ヒストグラム自体ははpandasのplot機能であるhistを使うことで容易に作成できます.ヒストグラムを眺めることで,実際に分散に違いがあることが視覚的にわかります.
wakuwaku.hist(bins=bins) mogumogu.hist(bins=bins)
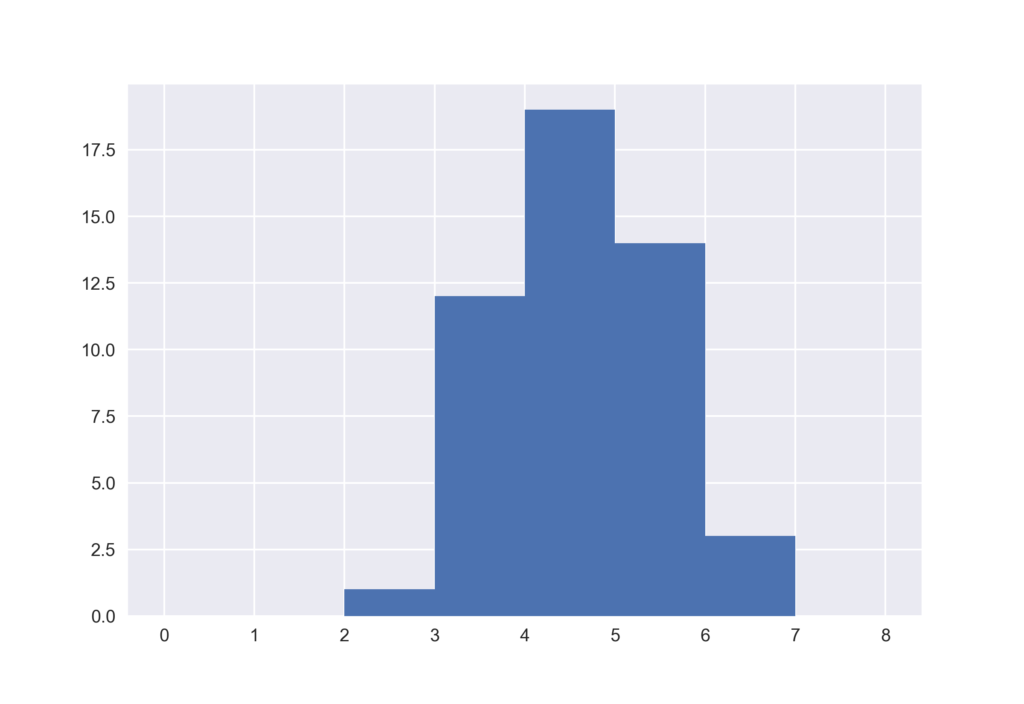
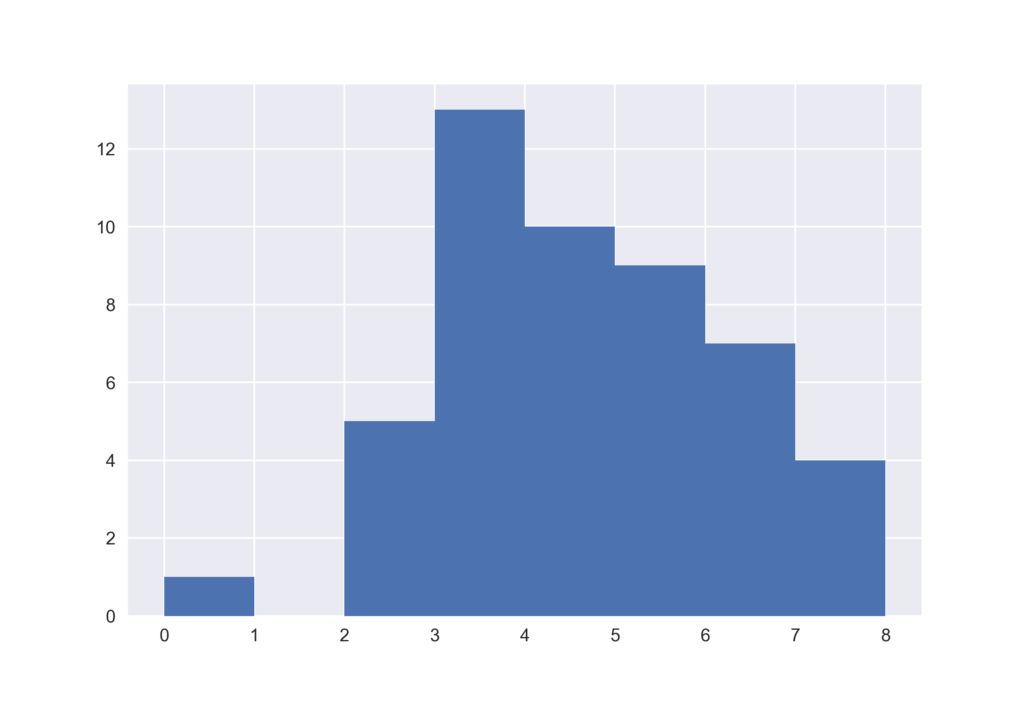
seabornを用いてヒストグラムを作成
続いてmatplotlibを基にした統計用グラフ作成ライブラリ,seabornを用いてヒストグラムを図示してみます.distplotという関数を使うことで可能です.seabornはsnsという名前でimportするのが一般的ですので,以下のコードでもそれに従います.
seabornではkde=Falseとすることで上記のpandsで作成したようなヒストグラムが得られます.
sns.distplot(wakuwaku, kde=False, bins=range(9))
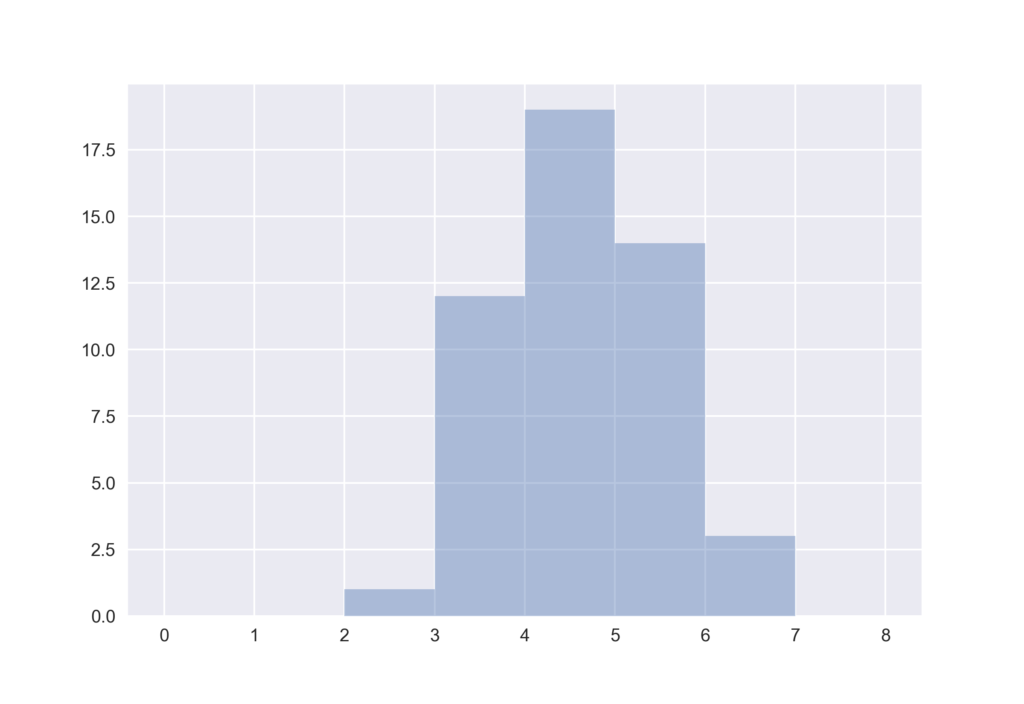
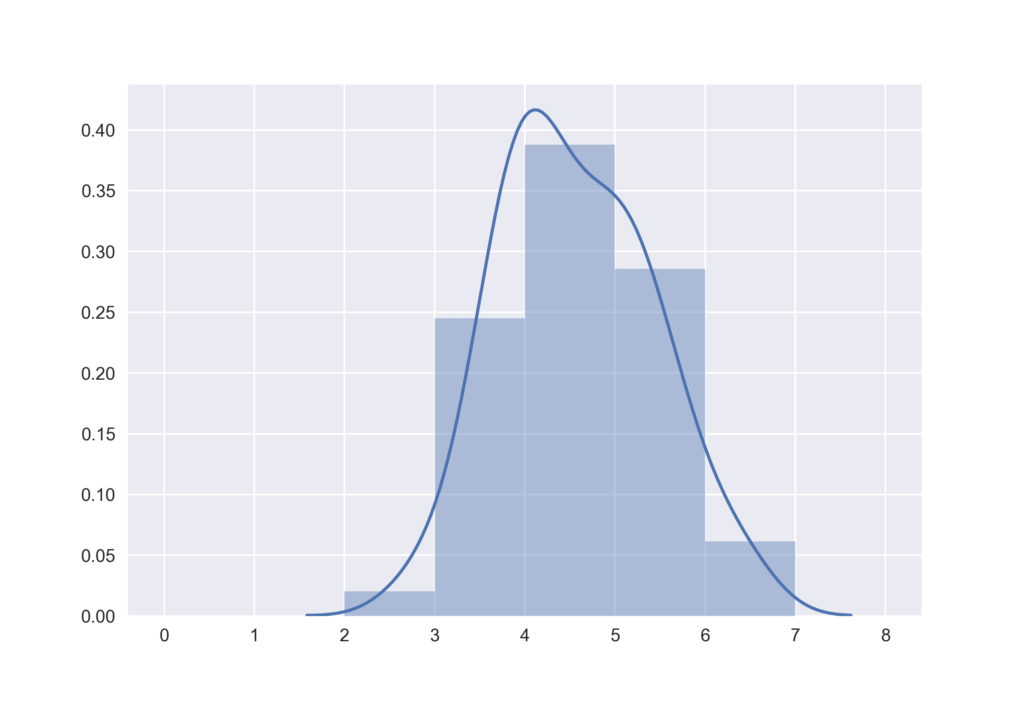
一方でseabornの通常設定では,ヒストグラムのカーネル密度推定を行いそれをヒストグラムに重ねて図示します.この際,ヒストグラムの面積の総和が1になるように縦軸のスケールが変更されます.つまり,面積値が確率に設定されます.
sns.distplot(wakuwaku, bins=range(9))
ヒストグラムを滑らかな曲線で表したものが追加されました.
バイオリンプロット
ついでに2つの店舗について,バイオリンプロットを描くことで視覚的に2つの違いを見てみます.今回のように2つの系列について,データの散らばりなどを把握したい場合にはよく使われる方法になります.
fig = plt.figure() ax = fig.add_subplot(111) ax.violinplot([wakuwaku, mogumogu], showmedians=True) ax.set_xticks([1,2]) ax.set_xticklabels(['wakuwaku', 'mogumogu'])

終わりに
今回はまず平均・分散・標準偏差についてpythonを使ってどのように扱うかを学びました.その際に
- pandasを使うことでこのような基本的な統計量が簡単に算出できること
- 標準設定では不偏分散が算出されること
を見てきました.続いて
- pandasのcut機能とvalue_counts機能を使うことで度数分布表が作成できること
- pandasのグラフ作成機能を使うことでヒストグラムが簡単に作成できること
を学びました.また最後にバイオリンプロットの作成方法も復習しました.
これだけでもpythonの便利さを垣間見ることができたかと思いますが,pandasをはじめとするpythonのデータ分析用ライブラリーには他にも有用な機能がたくさん用意されています.これから少しずつ学んでいきましょう.
>>次の記事:「pythonで統計学基礎:02 信頼区間・t分布」
コメント