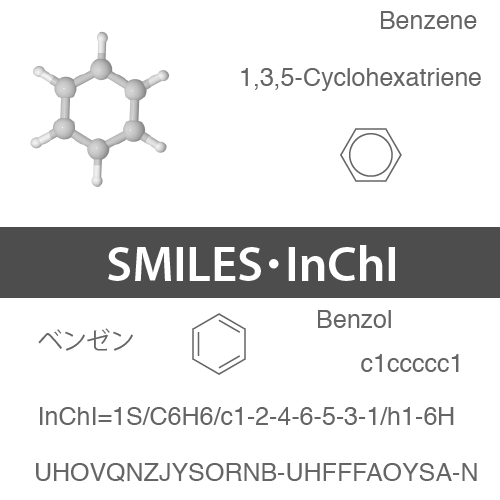
我々が普段使っている化学構造式は,コンピュータにとっては理解しにくいものです.そのため,コンピュータ上で構造情報を扱う際には,コンピュータに優しい方法に構造情報を変換したうえで扱う必要があります.
「MOLファイル・SDFとはどんな化学情報ファイルなのか?」という記事では,そのような形式の中でも「コネクションテーブル」というものを基にしたMOLファイルとSDFというものについて解説しました.
今回は「線形表記法」という分類の中で,
- SMILES記法
- SMARTS記法
- InChI記法
について説明していきたいと思います.いずれも少ない文字数で構造情報を伝えるための重要な表現方法になりますので,しっかりと理解を深めていきましょう.
化合物のグラフ表現
分子は原子をノード,結合をエッジと見なしたグラフと考えられます.グラフではある原子が他の原子とどのように繋がっているかを表現することができます.なお原子間の結合数がわかれば水素原子は後から付加可能ですので,コンピュータ上で分子を表現する際には水素原子は省略されることが多いです.
例えばプロパンは以下のように表すことができるはずです.

グラフ構造においては原子の位置は考慮せず,原子間の繋がりだけが重要ですので,「CCC」のように省略して書いても構造が頭に浮かぶのではないでしょうか?
このように分子の構造をある一定のルールに沿って,1行で表記するようにしたものが「線形表記法」と呼ばれる表現方法になります.
SMILES記法とは?
SMILES(読み方:スマイルス)記法とは,化合物の構造を1行の文字列で表記するための「線形表記法」の1つです.1986年にDavid Weiningerが提唱し,彼が共同設立者であったDaylight Chemical Information Systemsが開発を進めてきました.その簡便さからもっとも広く使われている線形表記法になります.なおSMILESは以下の6語の頭文字をとったものになります.
SMILES記法のルール
先ほどから述べているように,SMILES記法は一定のルールに沿って,化学構造を文字列へと変換していきます.ここでは簡単にいくつかのルールを説明していきますが,実際にはあらゆる構造を変換可能とするために細かいルールがあります.
- 原子は元素記号で表される.2文字の元素で紛らわしいもの(NbとNBなど)は[Nb]などのように囲む.
- 水素原子は省略する.
- 隣接原子は隣に記す.
- 二重結合は「=」で,三重結合は「#」で表し,単結合や芳香族結合は省略する.ただし,芳香族原子は小文字表記する(cなど).
- イオンなどの結合のない部分同士は「.」で分ける.
- 分岐構造は括弧()で表記する.
- 環構造は切断して鎖状構造とし,切断箇所を数字で示す(C1など).
これらのルールに従って作成したSMILESを「generic SMILES」と呼ぶことがあります.
さらに立体構造を示すために,
- 同位体は[13C]などのように表す.
- 絶対配置は「@」と「@@」で表す.
- 二重結合の幾何異性は「/」と「\」で表す.
といったルールがあります.これら同位体や不斉中心についての記述を含むSMILESを「isomeric SMILES」と呼ぶことがあります.
これだけではよくわからないと思うので,以下にいくつか具体例をまとめておきます.
| 化合物 | 構造式 | SMILES表記 |
|---|---|---|
| プロパン |  |
CCC |
| 鉄(II)カチオン | Fe2+ | [Fe+2] |
| 水酸化ナトリウム | NaOH | [Na+].[OH-] |
| 酢酸 |  |
CC(=O)O |
| フラン |  |
o1cccc1 |
| (S)-ブロモクロロフルオロメタン |  |
Br[C@H](Cl)F |
| (E)-1-ブロモ-2-フルオロエテン |  |
F/C=C/Br |
SMILES記法を統一するためのルール
さきほどのルールにはどの原子を始点とするかといった項目がありませんでした.例えば上のフランの例では酸素ー炭素結合の部分で環構造を開いていますが,炭素ー炭素結合で開いてもフランを表すことはできます.
実際の所,SMILES記法を構造式になおすだけならば,どのように表記しても問題ありません.しかし,「データベース中の化合物で同じ化合物が存在するかどうかを調べる」といった際には統一された表記になっていないと困ります.
そのためには,化合物名のIUPAC名に相当する,化合物に固有のSMILES表記があるとよいことがわかると思います.そのようなSMIELS表記を「カノニカル(canonical)SMILES」と呼びますが,まずはどのよう分子内の原子に序列・順番をつけていくかを見ていきましょう.
Morganアルゴリズム
分子内の原子の優先順位をつけるためのアルゴリズムの1つで,最も広く使われているものが「Morganアルゴリズム」と呼ばれるものになります.Morganアルゴリズムでは,原子の結合価(connectivity values)を反復によって決定していきます.具体的な手順は以下のようになります.
- 各原子に結合している原子数を書き出す
- 各原子に結合している原子の結合原子数をそれぞれ足し合わせ,原子の結合価を更新する
- 結合価の異なる原子数が一定になるまで2のステップを繰り返す
文字だけではまったくわからないと思いますので,以下ではアスピリンを例に見てみましょう.この例では4回目のステップまでは結合価の異なる原子数が3-6-8-11と増えていますが,5回目の終了時点でも11種類となっていますので,反復を終了します.原子の優先度はこの段階での結合価をもとに決定します.

実際には同点の場合などもありますが,その際には原子番号や結合次数などの他の要素を加味して,序列付けを行うことになっています.
カノニカル(canonical)SMILES
基本的には上述のMorganアルゴリズムに類似した「CANGENアルゴリズム」というものに従ってカノニカルSMILESは生成されます.このようにgeneric SMILESをカノニカルSMILESに変換することを「正規化(canonicalization)」と呼びます.
問題点はこのアルゴリズムの実装が商用になっていている点です.Daylight社のソフトウェアを用いた場合には同一のSMILESを生成しますが,他のオープンソースのソフトウェアなどは独自のアルゴリズムを採用し,同じ化合物でも異なるSMILESが得られるという事態が発生しました.
SMARTS記法
SMILES記法は非常に便利なので,これをもとにいくつかの拡張記法が開発されています.ここで紹介するSMARTS記法もその1つで,特に部分構造を表現し,データベース中での構造検索を行うために開発された記法になります.
例えば[C,N]は脂肪族炭素,または脂肪族窒素にヒットしますので,OR検索を意味します.他にもワイルドカード(全原子にヒットする)の「*」など,なんとなく見た目から意味が想像しやすい記号が多いです.またSMILESを発展させたものですので,SMILES表記そのものも有効なSMARTS表記になります.
以下にいくつか代表的な記号と例をまとめます.
| 記号 | 例 | 意味 |
|---|---|---|
| * | 全ての原子 | |
| a | c | 芳香族炭素 |
| A | C | 脂肪族炭素 |
| Hn | [*H2] | 水素が2つついている全ての原子 |
| R | [R] | 環内の原子 |
| Dn | [D3] | 結合が3つの原子.ただし省略されている水素は含まない. |
| Xn | [X3] | 全ての結合の合計が3の原子.省略されている水素を含む. |
| – | c-c | 芳香族炭素を連結する単結合(ビフェニルなど) |
| ~ | C~N | 脂肪族炭素と脂肪族窒素を結ぶ全ての結合(単結合,二重結合,三重結合) |
InChI
カノニカルSMILESは生成アルゴリズムが商用のため,自由に使えないという問題がありました.自由に使える化合物のカノニカル表記法の開発のために,1999年にSteve HellerとSteve Steinによって提唱されたのがInChI(読み方:インチ)です.その後IUPACとの共同開発によって2005年に最初のバージョンが発表されました.2009年からはInChI Trustという団体によって管理・開発されています.
InChIは,人間にも意味のわかる形で分子情報を表記したものです.全ての化合物が異なるInChIを与えるため,化合物名のIUPAC名に類似したものと考えてよいです.さきほど開発経緯から述べたようにカノニカルSMILESとの違いは,生成アルゴリズムが非営利で自由に使える点があげられます.
InChIの特徴
自由に使える化合物のカノニカル表記法を開発目標を掲げているInChIですが,次のような特徴があげられます.
- 生成アルゴリズムが非営利で自由に利用可能
- 構造情報のみで容易に計算できる
- 人間にもわかりやすい表記方法
こういった特徴から,PubChemやChemSpiderを始めとして,数多くの化合物データベースに採用されています.
InChI Key
ハッシュ化InChIとも呼ばれる,25文字固定長の分子表現です.InChIとは異なり,まれに異なる分子から同じInChIKeyが生成されることがあります.
SMILESやInChIの取得方法
データベースや試薬会社のウェブサイトから取得
SMILESやInChIは化合物データベースと相性がよいので,当然データベースの各エントリーから情報を取得できます.一方で試薬会社ではCAS番号などほどの知名度はないためか,記載されている会社は少ないです.ここでは化学データベースとしてPubChemとChemSpiderを,試薬会社としてSigmaAldrichのウェイブサイトを紹介します.
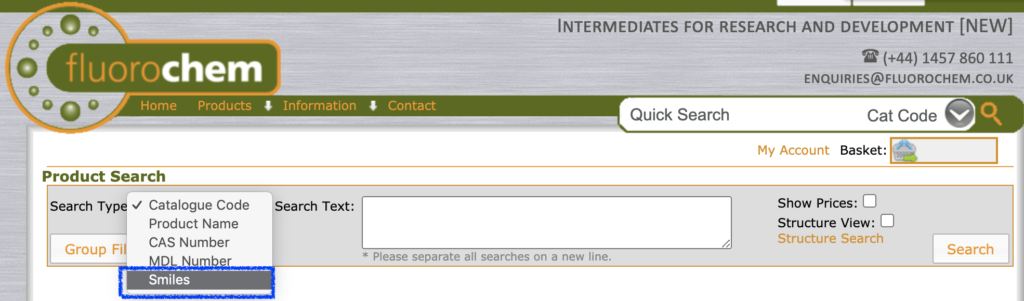
なお試薬会社の個別ページにはSMILESの記載がない場合も,検索などでは利用可能です.下はfluorochemの例です.
PubChem
PubChemではレコード最初の部分にInChI Keyがあります.

もう少し下がって,名称などの詳細データにInChI,InChI Key,SMILESが記載されています.

ChemSpider
ChemSpiderでは「More details」という項目の中にSMILES,InChI,InChI Keyが収載されています.

シグマアルドリッチ
シグマアルドリッチではInChI Keyが記載されています.

ソフトウェアやウェブサイトを用いて自分で作成
SMILES記法は汎用的な化合物情報フォーマットなので,多くのソフトがこれらの形式での書き出しに対応しています.ここでは実験化学者に馴染みのあるChemDrawによる方法と,ケモインフォマティクス用のpythonライブラリであるRDKitを使った方法,そしてウェブサイトからSMILESを作成する方法について触れます.
ChemDraw
描画した構造を選択し,「Edit -> Copy As」を選択するとSMILESやInChI形式での書き出しが可能です.

RDKit
RDKitでは2018.03のリリースからデフォルト設定でisomericSMILESを返すようになりました.またRDKitで生成されるSMILESは正規化されていますので,どんな方法でMOLオブジェクトを作成しても同じSMILESが得られます.
from rdkit import Chem
mol = Chem.MolFromSmiles('OB(O)C1=CC=C(C)C=C1')
Chem.MolToSmiles(mol)
# 'Cc1ccc(B(O)O)cc1'
Chem.MolToInchi(mol)
# 'InChI=1S/C7H9BO2/c1-6-2-4-7(5-3-6)8(9)10/h2-5,9-10H,1H3'
ウェブサイト
類似のサイトはたくさんありますので,ここでは1つだけ紹介します.たとえばSMILES generator/checkerというウェブサイトでは構造式を入力するとリアルタイムにSMILESを生成します.またInChIの生成も可能です.

終わりに
今回はコンピュータが扱いやすい化合物情報のフォーマットとして,「線形表記法」であるSMILES,SMARTS,InChIについて説明してきました.
「MOLファイル・SDFとはどんな化学情報ファイルなのか?」という記事で紹介したMOLファイルやSDFも含めて,化学情報を扱うファイル形式にはいろいろな種類が存在することが理解いただけたと思います.
次回はこのようなファイル形式を相互に変換するツールとして最も広く使われている「Open Babel」の使い方を解説していきます.
>>次の記事:「Open Babelを使って化学情報フォーマットを変換」
コメント